I did this research project at Systems Group, ETH, advised by Prof. Dr. Gustavo Alonso.
1. Targets
The goal of this project is to implement multi-threaded in-memory hash-based group-by aggregation on FPGA. When the cardinality of keys is low, like 210, we can build a hash table via on-chip memory (BRAM/URAM). But when the cardinality is high, like 220, on-chip memory is not big enough to store the whole hash table. In this project, I put the whole hash table in off-chip memory (HBM), which has a high read/write latency, and build a cache via on-chip memory (BRAM) to help hide the long memory latency.
2. Contributions
- Optimize the procedure to use Content-Addressable-Memory (CAM) as cache to reduce the number of requests of off-chip memory.
- Split the whole hash tables into several spans and store them in different HBM banks. Calculate hash values of input keys and distribute them to different Aggregation Engines (AE) to aviod concurrency problem. So that I only need to concatenate these local hash tables in the final stage and there is no need to shuffle and merge.
3. Introduction
Group-by aggregation is a combination of GROUP BY clause and AGGREGATE functions, which is used to obtain summary information from groups of rows in a table. The number of unique keys is called CARDINALITY. A concrete example is shown as below:

For single-thread operation, the common procedure is reading key-value pairs, calculating the corresponding hash values, read aggregation values from hash table, update and write into the hash table.
For multi-thread operations, if I insist the same procedure, different AEs may access the same HBM bank and there would be the problem of concurrency due to Read-After-Write (RAW) hazard. So I build local hash table for each AE and distribute key-value pairs to different AEs according to their corresponding hash values. The possible problem is the unbalanced hash distribution due to skewed data.
For on-chip cahce, I use CAM to do pre-aggregation to hide the latency of off-chip memory access and avoid RAW hazard.
4. Evaluation:
The design is evaluated in three datasets: uniform, hot-key, zipf. When the number of input key-value tuples is 64M, the throughput and CAM hit rate are shown as below:
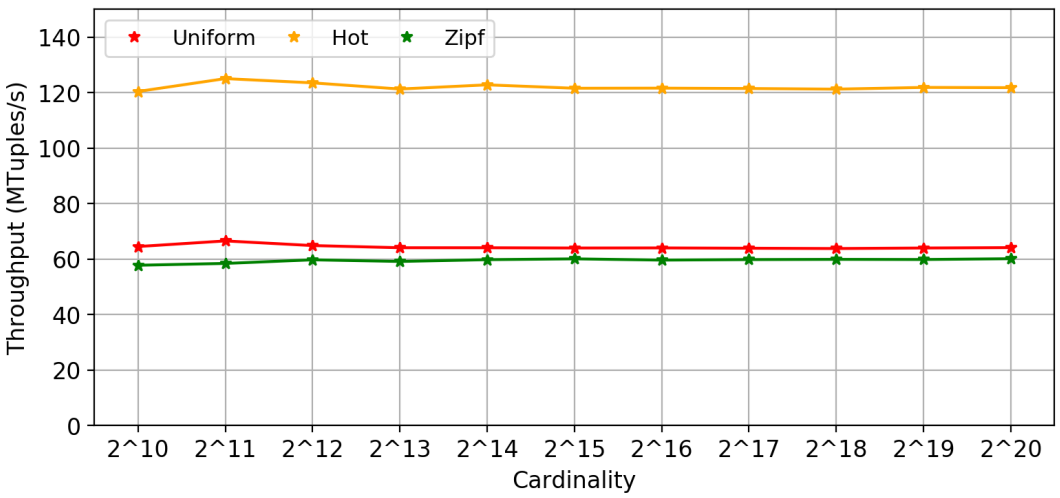
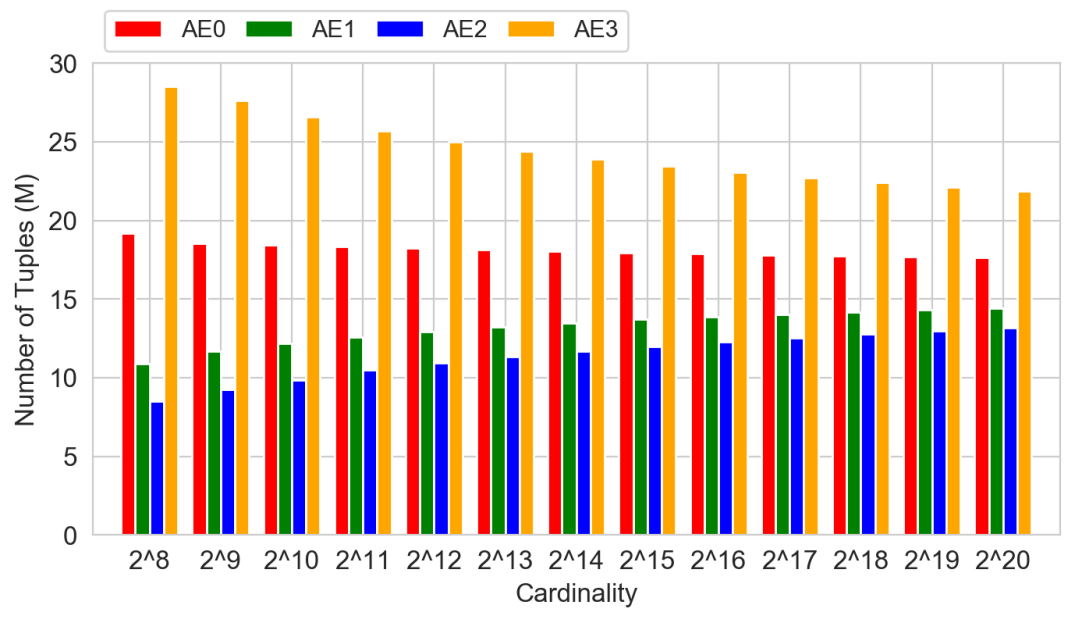
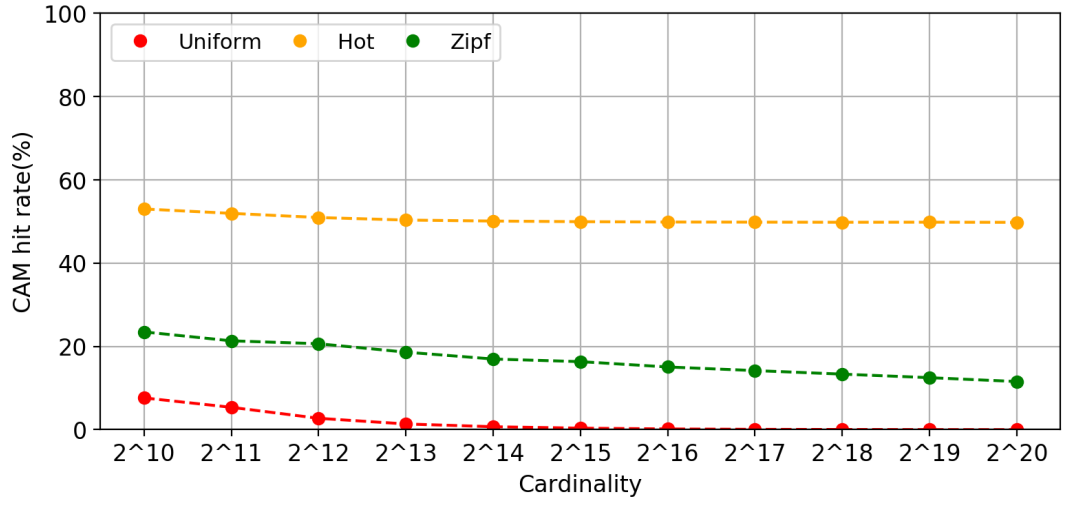 Distributing key-value pairs to different AEs according to their hash values may be unbalanced determined by the original key distribution. The AE which receives the most input tuples determines the final execution time. Zipf dataset is the most representative.
Distributing key-value pairs to different AEs according to their hash values may be unbalanced determined by the original key distribution. The AE which receives the most input tuples determines the final execution time. Zipf dataset is the most representative.
All the codes are written in HLS. For more details, please contact me.